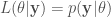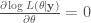Forney Style Factor Graph
by allenlu2007
Which Graph to Use
以下的四種 graphs 都可用來表示 p(u, w, x, y, z), 但並非等價。可以找到一些例子說明。
例如 Baysian network (directed graph) 的 V structure 無直接對應的 undirected graph. Undirected graph 的 loop structure 也沒有對應的 (acyclic) directed graph.
即使 undirected graphic 的 factor graph 和 markov random field (MRF) 也並非完全等價。Factor graph 以 factor 為單位,MRF 似乎以 clique 為單位 (?). 一般認為 factor graph 比較嚴謹且 general,但是太繁瑣因為同時要畫 variable and factor node (如下圖 original factor graph). Forney-style factor graph 用 arc 來取代 variable node, 只留下 factor node, 看來比較精簡。不過需要解決 shared variable (下圖的 X 連接兩個以上 factors) 的情況,因而引入 “=” 的 node.
一般有清楚因果關係的大多用 Baysian network. 各 variable 平等的應用大多用 MRF, 如圖像處理。Factor graph 在 error correction code 中常常使用。以下使用 Forney style factor graph.

Message Passing in Factor Graph
Message passing MP (or belief propagation BP) 分為兩類: sum product and max product.
在 factor graph 的 MP for sum product 如下圖所示。基本上以 variable 為單位

or with message passing:

可以 reuse message:

In general sum product and max product 可以用以下的 summary message. 針對每個相連的 factor 可以得到 summary message ( summation or maximisation of products of factor and all other incoming messages except for the outgoing one. 最後的結果是 summary message 的 products.
Step 1: compute all messages (starting at the leaves!)


在 loop-free 的情況下,sum-product algorithm:
Message Passing in MRF
MRF 的 message passing 兩個例子
1: Markov Chain (沒有 shared variable)

Node: variable X1, .. X5.
Factor: arc (每一個 factor 只有兩個 variable, no shared variable)
剛好和 Forney style factor graph 相反。
P(X2, X5) = P(X5) P(X2|X5)
P(X2|X5) : X5 是 evident node; X2 是 unknown node; 其他是 hidden node
所以 X2 看到的 message 為左右的 product. Format 和上文一樣:
sum of products: sig{ P(X3|X2) * delta(4) } and sig { P(X2|X1) * delta(1)}
2. Clique tree example (簡化後和以上相同)

Message Passing in WiKi


Wiki 的說法和之前的公式一致,只是分為兩部份。 messages: (variable v to factor u) and (factor u to variable v)
General Formula
Find P(X | Y) where X and Y are vectors
X: x1, x2, x3… are unknows
Y: y1, y2, y3… are evidences
Z: z1, z2, z3… are hiddens





























































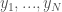 是實驗值。以及 x 是被估計的參數 (unknown),根據貝依氏的理論是一個 random variable.
是實驗值。以及 x 是被估計的參數 (unknown),根據貝依氏的理論是一個 random variable. 是 x 的 estimator, 以及估計的誤差
是 x 的 estimator, 以及估計的誤差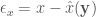
 , 或 loss function. 注意 cost function 仍是一個 random variable.
, 或 loss function. 注意 cost function 仍是一個 random variable.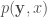 .
.![R = E[c(x-\hat{x}(\mathbf{y}))] = \int \int c(x-\hat{x}(\mathbf{y})) p(x,\mathbf{y}) dx d\mathbf{y}](https://s0.wp.com/latex.php?latex=R+%3D+E%5Bc%28x-%5Chat%7Bx%7D%28%5Cmathbf%7By%7D%29%29%5D+%3D+%5Cint+%5Cint+c%28x-%5Chat%7Bx%7D%28%5Cmathbf%7By%7D%29%29+p%28x%2C%5Cmathbf%7By%7D%29+dx+d%5Cmathbf%7By%7D&bg=fff&fg=444444&s=0&c=20201002)



![R_q = E[c(x-\hat{x}(\mathbf{y}))] = \int \int (x-\hat{x}(\mathbf{y}))^2 p(x,\mathbf{y}) dx d\mathbf{y}](https://s0.wp.com/latex.php?latex=R_q+%3D+E%5Bc%28x-%5Chat%7Bx%7D%28%5Cmathbf%7By%7D%29%29%5D+%3D+%5Cint+%5Cint+%28x-%5Chat%7Bx%7D%28%5Cmathbf%7By%7D%29%29%5E2+p%28x%2C%5Cmathbf%7By%7D%29+dx+d%5Cmathbf%7By%7D&bg=fff&fg=444444&s=0&c=20201002)

 相當於 minimize
相當於 minimize 
![\hat{x}_{MMSE} = \int x p(x|\mathbf{y}) dx = E[x|\mathbf{y}]](https://s0.wp.com/latex.php?latex=%5Chat%7Bx%7D_%7BMMSE%7D+%3D+%5Cint+x+p%28x%7C%5Cmathbf%7By%7D%29+dx+%3D+E%5Bx%7C%5Cmathbf%7By%7D%5D&bg=fff&fg=444444&s=0&c=20201002)



 .
.


 (non-random variable). 再
(non-random variable). 再