Python 語音特徵抽取-librosa 和 IPython 套件
by allenlu2007
Reference
[1] 陳昭明, “自動語音識別(Automatic Speech Recognition) — 觀念與實踐“
[2] M. Mandal in Medium, “Building a Dead Simple Speech Recognition Engine using ConvNet in Keras“
[3] Stanford CCRMA MIR 2018 Workshop, “Jupyter Audio Basics“
[4] Stanford CCRMA MIR 2018 Workshop, “Mel Frequency Cepstral Coefficients (MFCCs)“
前言
Neural Networks 在影像、文字、語音等自然使用者介面(NUI)處理有突破性的發展,之前我們已經見證過影像及文字的辨識威力了,從這一篇開始,我們要開始見識『自動語音識別』(Automatic Speech Recognition)方面的發展。
語音處理的概念
為了方便作語音辨識,與影像一樣,我們會對語音作特徵抽取(Feature Extraction),目前有 FBank、MFCC(Mel frequency cepstral coefficients) 兩種,特徵抽取前須先對聲音作前置處理:
- 幀(Frame)切割:通常每幀是25ms,幀與幀之間重疊10ms,以避免邊界信號的遺漏。
- 信號加強:針對高頻信號作加強,使信號更清楚。
- 加窗(Window):目的是消除各個幀兩端可能會造成的信號不連續性,常用的窗函數有方窗、漢明窗等。
- 去除雜訊(denoising or noise reduction)。

圖. 聲音前置處理,圖片來源:Preprocessing
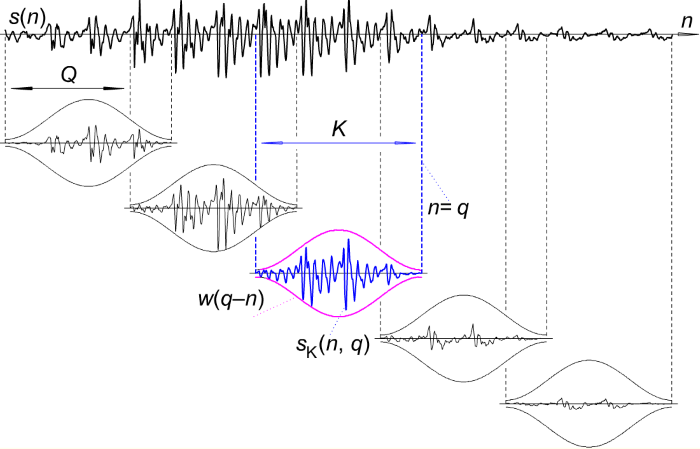
圖. Windowing and frame formation,圖片來源:Preprocessing
FBank相鄰的特徵高度相關(相鄰濾波器組有重疊),需要進行倒譜轉換,通過這樣得到MFCC特徵。MFCC具有更好的判別度,大多數語音辨識論文中用的是MFCC。
— 節錄自 kaldi之fbank和mfcc特徵提取

實作
有了以上的初步概念,我們先以一個簡單範例,揭開語音辨識的序幕。這個範例主要是根據一些事先標註的語音檔,辨識我們輸入的語音是哪一個單字? 範例的標註資料共有 bed、cat、happy 三個單字,分別有幾百個高低音的檔案,實作的方式,我們很熟悉,採CNN,流程如下:
- 利用 librosa 套件,對每一個音檔轉換成 MFCC 特徵向量。
- 將 MFCC 特徵向量轉換成 CNN 的 input 格式。
- 採取『阿拉伯數字辨識』一樣的CNN模型訓練。
- 任意指定一個音檔作測試,讀者也可以使用錄音程式,錄一個單字作測試,當然只能是bed、cat、happy 三個單字。
程式碼來自『Building a Dead Simple Speech Recognition Engine using ConvNet in Keras』,主程式為 DeadSimpleSpeechRecognition.ipynb 如下:




結論
這個範例只辨識 bed、cat、happy 三個單字,你可以加入更多的單字作訓練資料,只要放入不同的資料夾,程式完全不用改變,甚至放入中文詞檔,應該也沒有問題,因為程式只是辨識頻率,它根本分不清楚是哪一種語言。
Librosa and IPython Audio Package
librosa is a Python package for music and audio processing by Brian McFee. A large portion was ported from Dan Ellis’s Matlab audio processing examples.
IPython.display.Audio lets you play audio directly in an IPython notebook.
幾個 key functions:
IPython.display.Audio
librosa.load
librosa.display.waveplot
librosa.amplitude_to_db
librosa.display.specshow
librosa.output.write_wav
librosa.feature.mfcc

以下是 “happy” 的波形和 spectrum.


以下是 “bed” 的波形和 spectrum.

MFCC Feature [4]




